2つの1次元SOMでの独立成分分析はパラメータに対する感度が高い。
ちょっと非線形になると、結構調整しなきゃちゃんとなってくれない。
で、パラメータ設定がいらないっていうGTMをしらべて、訳してみた。
Christopher M. Bishop, et al.,
GTM: A Principled Alternative to the Self-Organizing Map,
1997
全訳orz...逐次学習の式載ってない。。
GTMで設定する必要があるのは基底関数だけらしい。
あとはEMアルゴリズムで全部学習するんだって。
SOMは1次元しか収束が証明されてないけど、GTMはちゃんと収束しますよ。
パラメータの設定が必要ないですよ。
っていうのが最大の売りかな。
最後のほうに
「我々はSOMがGTMアルゴリズムによって取って代わられると思う」
とあるのだが、ググってみると
self organizing map の検索結果 約 5,220,000 件
generative topographic mapping の検索結果 約 76,500 件
約70倍の差がある。。日本語限定だと
self organizing map に一致する日本語のページ 約 15,100 件
generative topographic mapping に一致する日本語のページ 約 115 件
約130倍。。
つまりまだまだ普及していない、と。
とりあえず逐次学習の方法はもう少し長い論文よめって事ですか。。
6ページの論文で1日がかりだったから、112ページの
博士論文だと・・・
2週間以上orz
せめて
16ページのものをやりたいとこだけど、もうSOMでいいや。
めんどくさいし。

あ、こんなんだから普及しないわけね。納得。
 [2回]
[2回]
PR
この前研究がんばるとか書いときながらあんまり進んでない。。
タイトルのやつ、やってみた。
田尻 隆 ,倉田 耕治,二つの1次元SOMの結合による独立成分分析と主成分分析,2004でもあんまりうまいこといかない。。
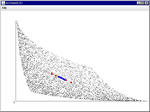
結果はこんな感じ。
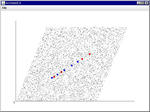
フィードフォワード抑制結合モデル
リカレント抑制結合モデル
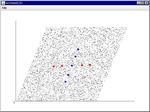
リカレントの方はちゃんとなってるけど、フィードフォワードの方はうまいこといかない。
なんで?
まぁ原理が原理だけに第2主成分の方がちゃんと対角線を向くとは思えないんだけど。。
単なるSOMに対して同時に発火しないように抑制してるだけだし。
というかリカレントの方がうまくいってびっくり。
ただ、これでなにができるの?
音声分離でもできれば面白いけど、どうつかえばいいのかわからない。。
まともに勉強したのPCAだけだし。
これが何を表してるのかもわからない。
とりあえずPCAの観点からいくと主成分得点を各SOMの重みが表してるんだろうけど、
それがわかったら次どうすればいいんだろう?
先は長そうだ。。
[0回]
久しぶりに日記。
しばらく論文ばっか読んでた。
しんどい。
「しんどい」って方言らしいね。知らんかった。
ICAを勉強しようとしたんだけど、むずい。
PCAしかわからん。
そろそろプログラム書きたい。
歩行とかジャンプとかするロボット作る場合ってソレノイド使った方がよくない?
力強いし。ストローク短いけど。
パラレル駆動で細い奴(100円くらいの)を何本か使えば面白いと思うんだけど。
OpenHRP3が一般公開されたね。
でもMicrosoft Robotics Developer Studioもある。
OpenHRP3は説明が日本語なのがよい。でも説明不足。
MSRDSは英語だからしんどい。でもサンプルが多いから何とかなる、かも。使ってない。
やっぱ開発環境ってUNIX系が主流だね。
いろいろロボットシミュレータを探してみたけど、ほとんどLinux。
前にLinux使おうとして挫折したからなぁ。。
そもそもLinux使うためにPC再起動しなきゃいけないというのがダメだ。
でも仮想マシンだと遅い&容量食う。
なんとかLinux環境になれる方法はないものか。
まぁMinGWとかCygwinで十分なんだけど。
研究の内容ってブログ公開しちゃダメなんだろうか。。
これは自分の研究じゃなくて大学の研究だからダメっていわれる?
でも自分で研究テーマ決めたし、教授ですら内容把握してないし。
別に革新的な研究をやってるわけじゃないからいいとおもうんだけど。。
アクセス履歴見てたら面白い。
いろんな企業とか大学からアクセスがある。
さすがにこの内容で日本語だと目に付くんだろうな。
というわけで土日に研究がんばります。
[0回]
この前のSOMからHMMのパラメータ学習はやめ。
バッチ学習してるらしい。ちゃんと読めよ。というか翻訳してるときに気づけよ。
やっぱ逐次学習でしょ。うん。
オフライン学習とか面白くないし。
で、強化学習へ。
どっちにしてもロボットを動かそうと思ったらまず強化学習だし。
今はBESOMとHTMの合成を考えてるわけだけど、どっちもベイジアンネット。
というわけでベイジアンネットに使える強化学習を探してみた。
山村雅幸:“Bayesian Network 上の強化学習”,第 24 回知能システムシンポジウム,. pp.61-66,(1997)
これ読みたい。でもネット上に落ちてない。論文取り寄せとかしたことない。
しかたないから
山村研究室にあった
修士論文でガマン。
これでも十分にわかる。かなりよい。
これでBESOMの強化学習の部分いけるんじゃないかな?
以前からCPTは強化学習の対象になると思ってたけど、Q-Tableで考えてた。
まさかactor-criticだとは。でも、こっちのほうがいい感じ。
すごいね、山村先生って。
[0回]
SOMを使ってHMMのパラメータを推定できるらしいよ。
とかいいつつまだ完全には理解できてないよ。
だから翻訳も怪しいよ。
COMPETING HIDDEN MARKOV MODELS ON THE SELF-ORGANIZING MAPつ
全訳HMMの学習には segmental k-means とかいうものを使ってるらしい。
音声認識の分野では音素切り出しに使う一般的な方法のようだ。
HMMの学習法ってBaum-Welchしか知らなかった。
まだまだ勉強が足りませんなぁ。。
日本語情報が少ない。
セグメンタルK平均、セグメンタルK-means、分割K平均とか色々訳されてるし。
本文によるとBaum-Welchが全体を修正するのに対して、
segmental K-meansではViterbiアルゴリズムを使って最尤系列のみ修正するらしい。
で、近傍学習もやって、うまいこといきましたよって話らしい。
しかしこれだけじゃちょっとわからん。
博士論文でも読むか、あと
これも読まなきゃダメなのかな?
なんか前の
HMM-SOMよりもいいかも。
まだ比較してないんだけど、学習データをシフトさせてBaum-Welchかけるより
segmental k-meansで少しずつ学習していったほうが学習しやすい気がする。
だってHMM-SOMの方法って、結局リカレントネットのBPTTと変わらんし。
あ、そこで
シナプス前抑制を使うわけ?
この論文って著者がその後の研究してないんだよね。
博士論文が出てるから2000年で卒業して他の研究に移ったって事だな。
こっちの人も1998年で研究テーマ変えてるし。。
もしかしてすでにこの手法はダメだってわかってるのか?
[0回]